

We are customer-centric and provide customized or one-stop full-stack solutions to empower all industries.
High performance computing refers to computing systems and environments that usually use many processors (as part of a single machine) or several computers organized in a cluster (operating as a single computing resource). Applications running on high-performance clusters generally use parallel algorithms to divide a large general problem into many small sub-problems according to certain rules, and calculate them on different nodes in the cluster. The processing results of these small problems can be combined into the final result of the original problem after processing. Since the calculations of these small problems can generally be completed in parallel, the processing time of the problem can be shortened. High performance computing occupies a fundamental position in a country’s scientific research and is one of the driving forces of scientific and technological innovation. High performance computing represented by E-class supercomputers has broad application prospects and is expected to “show its prowess” in fields such as climate science, renewable energy, genomics, astrophysics, and artificial intelligence.
Specifically, GPUs are designed to solve problems that can be expressed as data-parallel computations—programs executed in parallel on many data elements with extremely high computational density (ratio of mathematical operations to memory operations). Since all data elements execute the same program, there is less demand for precise flow control; and because it operates on many data elements and has a high computational density, memory access latency can be hidden through computation without having to use large data caches.
Data parallel processing maps data elements to parallel processing threads. Many applications that process large data sets can use data parallel programming models to accelerate computation. In 3D rendering, large sets of pixels and vertices are mapped to parallel threads. Similarly, image and media processing applications (such as post-processing of rendered images, video encoding and decoding, image scaling, stereo vision, and pattern recognition) can map image blocks and pixels to parallel processing threads. In fact, many algorithms outside the field of image rendering and processing are also accelerated by data parallel processing – from general signal processing or physical simulation to mathematical finance or mathematical biology. In the above fields, GPU computing has been successfully applied and achieved incredible acceleration results.

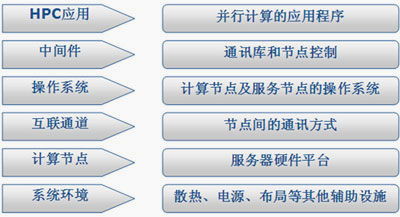
The high-performance cluster promoted by Boya is a super parallel computer cluster system designed specifically for large-scale analytical computing. It follows Intel’s open HPC ecosystem architecture to systematically deploy all software and hardware: Intel’s dual-core Xeon and multi-core Xeon based on the Core architecture are used as computing nodes. Boya’s high-performance computing cluster adopts a cluster architecture, interconnects through a standard open high-speed network, runs an open source Linux system, and provides a single system interface to the outside world. It is designed for large-scale scientific parallel computing, taking into account transaction processing and network information services.
This solution mainly builds management nodes, computing nodes, and distributed storage resource pools to build a high-performance computing cluster with a computing power of more than 100 Tflops. Storage uses high-performance and low-latency SSD distributed storage pools and large-capacity HDD distributed storage pools to meet the needs of high-performance computing power and high-speed storage IO bandwidth.
【Hardware parts】
Compute node: CPU compute node
Management node: dual-core server
Login node: dual-core server
Storage nodes: distributed parallel storage
Network system: including Ethernet network system, fiber storage network, cabinets, PDU, etc.
【Software】
Operating system: CentOS 7
Cluster software: resource management and scheduling software Powercloud
Development environment: Fortran/C/C++, etc.
Parallel environment: OpenMP, OpenMPI, MVPAICH2 and other MPI parallel environments
File system: Distributed parallel file system
Application software: Customers bring their own application software

The computing network uses a high-speed 100G IB network to ensure that the user's computing tasks are not limited by network bandwidth during operation. The business network uses 25G Ethernet, which has low latency and high speed. The two-layer high-speed network ensures that all nodes in the cluster can run at full line speed without blocking, which can fully meet the needs of high-speed interconnection.
The computing nodes are composed of PowerLeader four-way servers, each of which can support four Intel Scalable Series processors and a maximum of 96 memory slots, multi-core computing power and large memory operation capabilities, providing power for demanding HPC and scale-out workloads.
Storage resources are divided into two distributed resource pools, where the SSD storage pool runs important data and hot data, and the HDD storage pool stores cold data and large-capacity data, taking into account both IO performance and capacity.
The entire cluster adopts a variety of reliability design solutions to greatly improve the reliability of the system and ensure that the system has no single point of failure. At the same time, it provides users with a simple and easy-to-use use and maintenance interface, lowers the threshold for system use and maintenance, and improves the maintenance efficiency of the entire system.